读《软件测试的艺术》
缘起
看完了《富足》之后继续在公司的书架上淘书,偶然看到了一本薄薄的小书《软件测试的艺术》,英文名是 《The Art of Software Testing》。本书出版于 1979 年,距今已经快 40 年了,我手里拿的是第三版。粗粗翻了下,虽然书很久远,但还是有一些挺有意思的观点,所以花了几天时间把它读完了。
我一开始编程完全不知道有测试的概念,后面了解到 TDD,在项目中实践了下,但是有感于测试用例编写的繁琐,最后又废弛了。后面慢慢的又开始写测试了,因为高效的编程离不开测试。测试可以解放我们的大脑,专注于面向接口编程而不需要记住所有接口的内部逻辑,更不要说随之而来的减少 Bug,方便重构等好处了。
概览
整体书主要内容分为二部分。首先是软件测试的心理学,如果你不是从心底认为测试是一个好东西,又怎么能真正重视测试呢。然后是测试的方法论,讲解如何高效的编写测试用例。
正文
因为对测试我本身就怀有很多的疑惑,所以这里以问答的形式总结本书的内容和给我已启发的地方
什么是测试
我:为了保证我们编写的代码正常运行而实行的校验措施,提高我对程序能实现预期功能并在生产环境正常运行的信心。
作者:软件测试是为了发现程序错误而执行程序的过程,是为了增强软件的可靠性。
评论:我以前对测试的态度是消极的,对我编写的代码块来说,我一般认为它是能正常运行的,或者说它大概率能实现我的所思所想,而我写测试只是为了对这个大概率正常的代码进行进一步的验证,可能我多花了一半的时间,但是只剔除了小概率会失败的情况。而作者正好相反,他预期我们的代码大概率蕴含错误,而我们多花一半的时间,剔除了大概率会失败的情况,由此测试的价值大大增加。自然我们内心也有了更强的动力去写测试,毕竟谁不喜欢投入低,产出高的事情呢?
以简单的数学论的话:
假设正常完成的代码块的价值为 1,我投入 10 个单位时间完成功能代码的编写,如果有 90% 的概率能正常运行,此时代码价值为 10 * 0.9 = 9,编码单位时间价值为 0.9 / 10 = 0.09,此时投入 5 个单位时间编写测试,确保剩下的 0.1 个单位的软件价值,则测试单位时间的价值为 0.1 / 5 = 0.02,如果投入 2 个单位时间进行测试,则价值为 0.1 / 2 = 0.05,编程效率分别是之前的 22.22% 、 55.55%。我想任何一个对效率有所的追求的人都很难满意,更不要说跟创造带来的愉悦感相比,测试的编写是个相对无聊的过程。
而作者假设投入 10 个单位时间完成编写过程后,编写的代码只有 50 % 的概率能正常运行,此时代码价值为 10 * 0.5 = 5,单位时间价值为 0.5 / 10 = 0.05。如果我投入 5 个单位时间编写测试,确保了剩下的 0.5 个单位的软件价值,则编写测试单位时间的价值为 0.5 / 5 = 0.1,如果投入 2 个单位时间进行测试,则测试单位时间价值为 0.5 / 2 = 0.25,编程效率为之前的 100% 、 250%。
总结成公式的话,假设 p 为先验代码正确率,Vt / Vc 为测试/编码价值之比,t / c 为测试时间/编码时间, 则公式如下
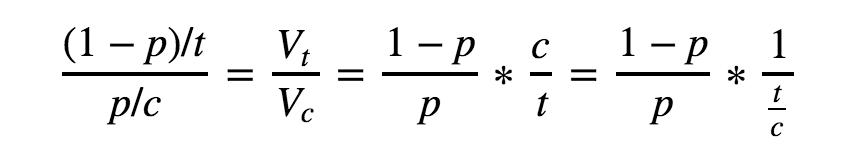
转化成图表如下:
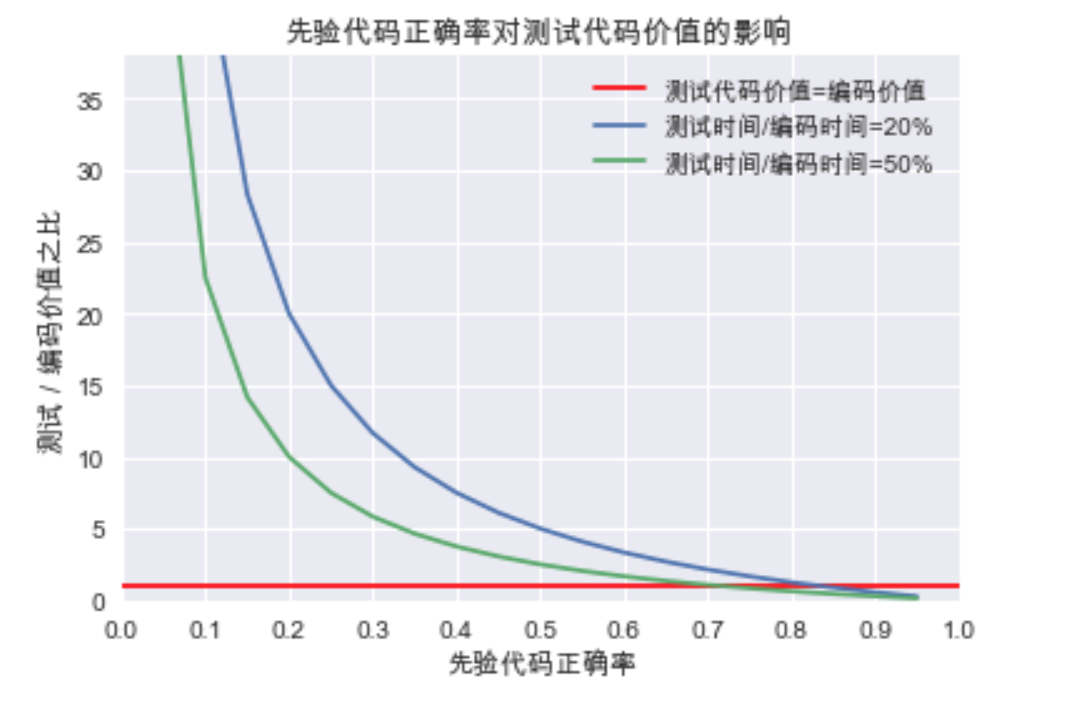
可见测试的代码价值随着我们对代码正确率信心的下降而指数级上升。在这个复杂的现实世界中,懒惰而又讲究效率的程序员反而会成为测试的坚定拥护者。
为什么我们要写测试
主要有三方面:
一、编写测试可以保证代码实现了我们需要的逻辑,不至于到线上才出现一些低级 Bug。
二、测试可以快速重复多次运行,节省我们每次修改完代码后花费无聊、痛苦的手动测试时间。
三、写测试的过程可以理清我们代码的逻辑,毕竟你不能对一个你自己都不了解要做什么的代码块编写测试。
作者: 软件的运行应当是可预期、稳定的,符合最小惊异原则,软件测试是实现这一目标的手段。据统计分析,每千行代码一般蕴含 1-25 个错误,而测试的目的就是为了找出相关错误。
什么是成功的测试?
我: 没有发现错误的测试就是成功的测试
作者: 发现错误的测试才是成功的测试。类比于对病人做检查,正确查出病因的检查才可称为成功或者有效,测试同样如此。
这里作者提到一个挺有意思的心理学原理,当人知道自己的目标无法达成或者自认为无法实现时,表现会非常糟糕。
为什么测试往往难以落实到实践中
我:
一、测试用例编写编写不当,很多时候对的逻辑可能只有一条,但是错的逻辑有千千条,一开始投入编写测试用例的时间会降低增加软件开发的效率,而无法高效的编写测试用例也会导致对测试心生厌烦。
二、一开始没考虑到模块化、测试的需求,导致后期无法高效的 mock 数据,测试成本过高。
三、测试没有集成到开发流程中,导致有时候测试被破坏没有修复,根据破窗效应,后面的废弛也是预料之中了。
作者:在复杂的现实中,对软件进行完全的测试貌似是不可能的任务,但是我们可以通过相关的方法和技巧提高测试的效率,以达到可以享有测试的大部分好处而不至于投入过多的时间。
而如何高效的测试也是我最有兴趣把本书看完的动力
测试的方法论
测试的几个原则
以下是我感觉比较有意思的
- 通过有限的测试用例,尽可能多的发现错误:如何更有技巧的编写测试用例
- 测试需要多次重用:持久化测试用例的价值
- 程序某部分已发现的错误跟其未发现的错误成正比:如何分配测试用例的精细度
- 需要对无效输入进行测试:防御性编程
白盒测试
条件/判定覆盖
书里面提到的覆盖条件计算比较复杂,可以用《代码大全》里面提到的简化版来决定测试用例数
- 默认测试用例为 1
- 遇到 if / else / for / while 等条件语句,测试用例数加 1
黑盒测试
等价类划分
尽量将输入范围划分为几个等价类,使得对某个等价类元素的测试等同于对整个集合的测试。同时区分有效等价类和无效等价类。如果可能的话对输出范围也进行等价类划分。
边界值测试
测试用例的选取尽量选择边界值。边界值一般为上边界、上边界 + 1、下边界、下边界 - 1
错误猜测
尽量选取一些容易导致出错的特殊值,比如 0、None、空数组等等。这个更加依赖于程序员的经验和对编写代码的理解。
因果图分析
这个方法我没看懂,有理解的欢迎在下面回复。具体好像是利用了一些数理逻辑的方式进行了非常复杂的逻辑推断最后得出如何编写对应的测试用例。
测试的编写
以下面这个小函数为例
def double_if_less_than_ten(num):
if num < 10:
return num * 2
return num- 条件/判定覆盖:默认为 1,遇到一个 if 加 1,最后需要至少 2 个测试用例
- 等价类划分:有效等价类为
(num < 10)以及(num >= 10),无效等价类为(num 不为数字) - 边界值测试: 上边界相关临界值可取
9,10 - 错误猜测: num 可取
0
综合以上的条件,便可选取尽量少的测试用例覆盖尽量大的测试范围。
| num | expected_value | 满足条件 |
|---|---|---|
| 9 | 18 | if 为 True、(num < 10)、边界值为 9 |
| 10 | 20 | if 为 False、(num >= 10)、边界值为 10 |
| 0 | 0 | 错误猜测 0 |
| None | raise TypeError | 无效等价类 (num 不为数字) |
尾声
《代码大全》里面提到,越好的程序员越是谦虚,因为他们明白编程是为了弥补人有限的智力,因此愿意通过学习来弥补。而编程糟糕的程序员往往自负,为此失去了提升自我的机会。对测试而言,我觉得下面这句话总结的很好,以此自勉。
Form is liberating